新开普:星普大模型内部测评智能推理效果与DeepSeek-R1相近 算力消耗约其1/20
人民财讯3月7日电,新开普(300248)3月6日在机构电话交流会表示,公司自研的星普大模型,通过SFT+RL(监督微调+强化学习)的训练技术,在内部测评验证中,实现了与DeepSeek-R1相近的智能推理效果,而算力消耗仅约为其1/20,下一步将参加行业评测,以获取行业公认数据。算力消耗降少可降低硬件投入,节约的算力预算可以为让渡给软件提供了空间,为更多软件、智能体服务及智能应用提供增加预算的空间,在降低算力硬件投入的同时仍要保证使用体验与服务精度。
声明:
- 风险提示:以上内容仅来自互联网,文中内容或观点仅作为原作者或者原网站的观点,不代表本站的任何立场,不构成与本站相关的任何投资建议。在作出任何投资决定前,投资者应根据自身情况考虑投资产品相关的风险因素,并于需要时咨询专业投资顾问意见。本站竭力但不能证实上述内容的真实性、准确性和原创性,对此本站不做任何保证和承诺。
- 本站认真尊重知识产权及您的合法权益,如发现本站内容或相关标识侵犯了您的权益,请您与我们联系删除。



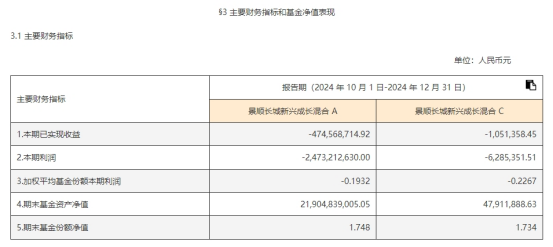
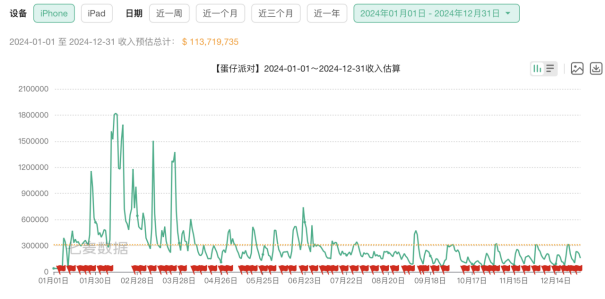
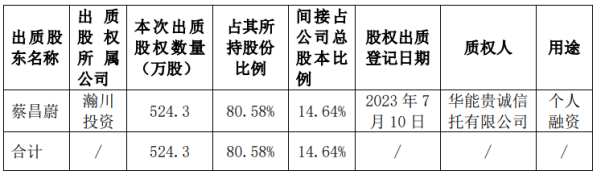





推荐文章: