阿里巴巴发布新一代端到端多模态旗舰模型Qwen2.5-Omni
阿里巴巴发布了新一代端到端多模态旗舰模型Qwen2.5-Omni,号称具备全方位多模态感知能力,看听说写样样精通。
采用全新的Thinker-Talker双核架构,Thinker模块负责处理多模态输入并生成语义表征和文本内容,Talker模块则负责将这些信息转化为流畅的语音输出。这种架构实现了端到端的统一,支持实时音视频交互和流畅的语音生成。
能够无缝处理文本、图像、音频和视频等多种输入形式,并同时生成文本和语音输出。支持分块输入和即时输出,实现真正的实时交互。
已在Hugging Face、ModelScope、DashScope和GitHub等平台开源,方便开发者体验和使用。
相比现有方案,语音生成的自然度和稳定性更高。在音频能力上优于同等规模的Qwen2-Audio,与Qwen2.5-VL-7B保持同等水平。在语音指令理解方面表现出色,效果可媲美文本输入。
声明:
- 风险提示:以上内容仅来自互联网,文中内容或观点仅作为原作者或者原网站的观点,不代表本站的任何立场,不构成与本站相关的任何投资建议。在作出任何投资决定前,投资者应根据自身情况考虑投资产品相关的风险因素,并于需要时咨询专业投资顾问意见。本站竭力但不能证实上述内容的真实性、准确性和原创性,对此本站不做任何保证和承诺。
- 本站认真尊重知识产权及您的合法权益,如发现本站内容或相关标识侵犯了您的权益,请您与我们联系删除。
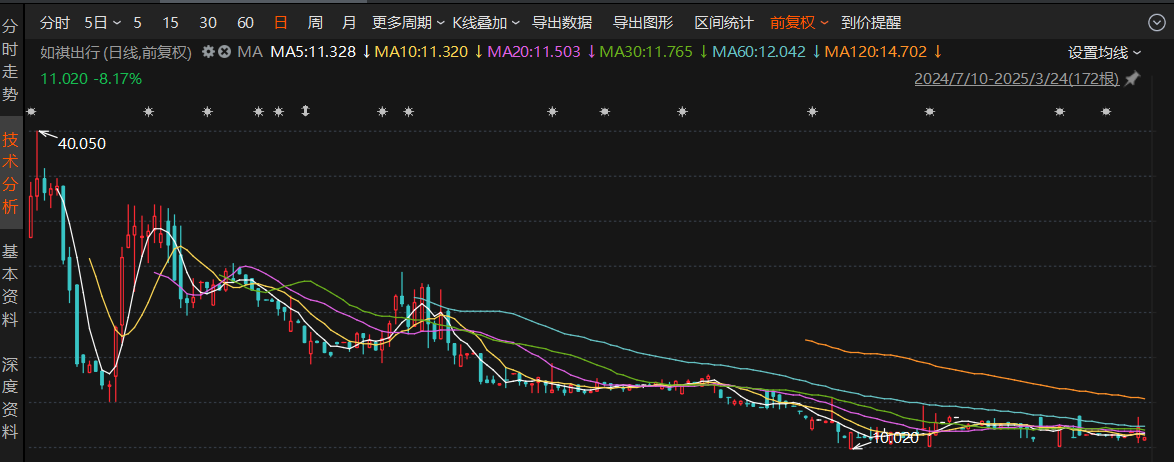
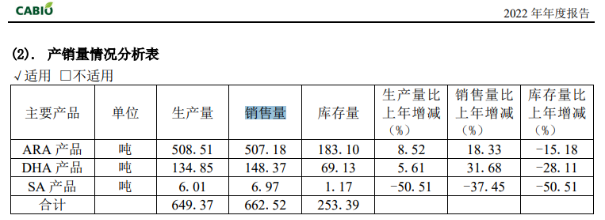

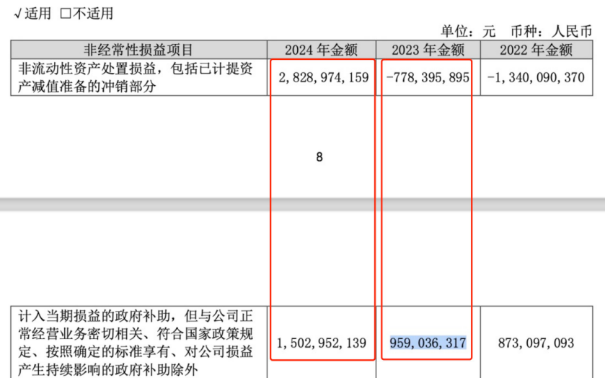







推荐文章: